By Paulo Frugis – Elevata’s CTO
We are witnessing a quiet but violent shift in the software landscape. For the past two years, the industry has been in the “Honeymoon Phase” of Generative AI, obsessed with Chatbots, Copilots, and RAG (Retrieval-Augmented Generation) systems that summarize PDFs.
That phase is ending. The market is no longer rewarding novelty; it is demanding execution.
The next frontier is not about talking to an AI; it is about assigning work to it. We are moving toward Frontier Agents—autonomous software systems capable of receiving a high-level instruction (e.g., “Upgrade our Java 11 microservices to Java 17 and fix any breaking changes”), working on it for days, navigating errors, and delivering a production-ready Pull Request.
However, most engineering organizations are walking into a trap. They are attempting to build these autonomous agents using the same architectural patterns they used for stateless web apps or simple chatbots. This is a catastrophic mistake.
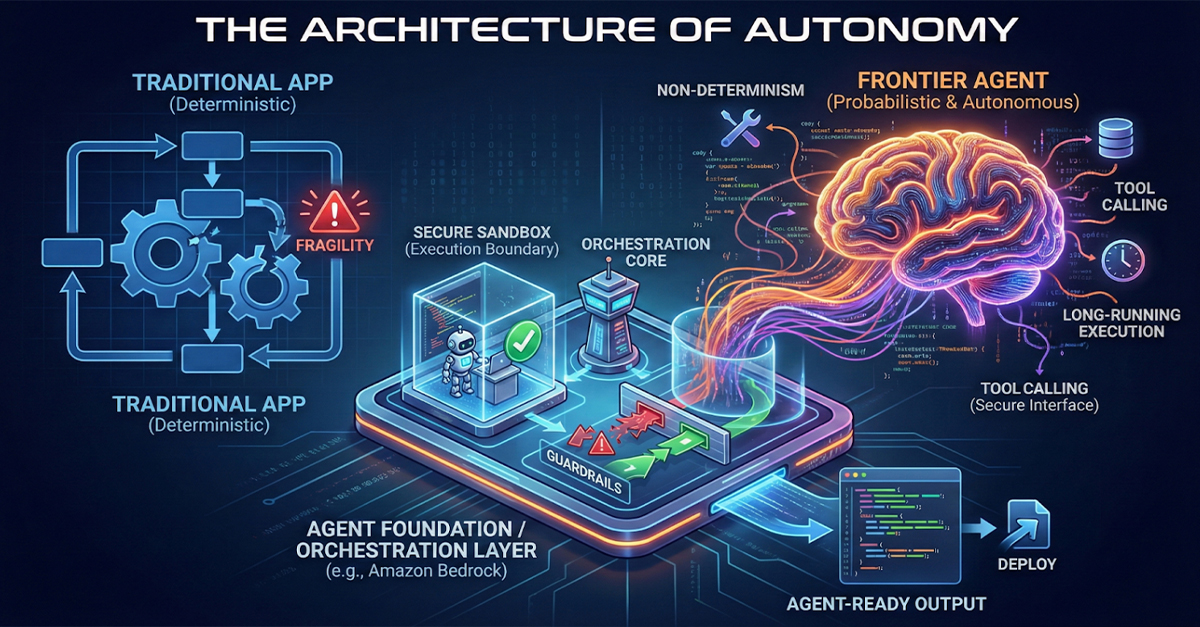
Agents are fundamentally different from traditional applications. Treating them the same causes fragility, security risks, and massive cost blowups. To move from “Toys” to “Digital Employees,” we need to understand why the old architecture fails and define the new Agent Foundations required to succeed.
The Core Friction: Probabilistic Minds in Deterministic Systems
To understand why “just adding an LLM” to your backend fails, you must appreciate the fundamental clash between modern software engineering and Artificial Intelligence.
Traditional software is deterministic. When you write a unit test for a banking API, you expect 10 + 10 to equal 20 every single time, down to the millisecond. Our entire DevOps ecosystem—CI/CD pipelines, linters, compilers—is built on this assumption of predictability.
Frontier Agents, however, are probabilistic. Run the same prompt through Claude 3.5 Sonnet or GPT-4o three times, and you might get three slightly different approaches to solving a coding problem.
When you embed a probabilistic “brain” into a deterministic pipeline, you introduce chaos.
- The “Flaky Test” on Steroids: In traditional software, a flaky test is an annoyance. In Agentic workflows, “flakiness” is a feature of the intelligence engine.
- The Cascading Hallucination: If a standard microservice fails, it throws a 500 error and stops. If an Agent “fails” (hallucinates), it often continues confidently, stacking bad code on top of bad logic for hours before anyone notices.
This friction creates three distinct challenges that your platform must solve: Non-determinism, Tool Calling complexity, and Long-Running Execution.
What Makes Agents Different? (The Three Vectors of Chaos)
1. Non-Determinism and the “Validation Gap”
In a standard app, you validate inputs. In an Agentic app, you must validate reasoning. An agent tasked with refactoring a Python script might decide to swap a library for a more modern one. This isn’t just a syntax change; it’s a semantic decision. A deterministic pipeline cannot catch this if the code technically compiles. The Risk: You cannot rely on “Golden Datasets” or static unit tests alone. You need dynamic evaluation environments that can judge the intent of the code, not just its syntax.
2. Tool Calling: The “Hands” of the Agent
A text-generation model (Chatbot) is safe because it lives in a padded room. An Agent is dangerous because it has hands. To function, an Agent needs tools: access to the file system, ability to run shell commands, git access, and database query rights. The Problem: LLMs are notoriously bad at adhering to strict API schemas over long contexts. They might “hallucinate” a parameter that doesn’t exist (–force-override) or misuse a destructive tool (rm -rf) based on a misunderstood instruction. The Architecture Gap: Standard API Gateways are designed for authenticated humans or code, not for “fuzzy” intent from an AI. You need an intermediary layer that sanitizes and validates tool use before it hits your infrastructure.
3. Long-Running Execution and State Drift
This is the silent killer of agent projects. A user chat session lasts 5 minutes. A complex software engineering task (e.g., “Analyze this 50-file repository and implement a feature”) can take hours or even days of autonomous work.
- The Context Window Trap: As the agent works, it generates logs, diffs, and thoughts. This data quickly exceeds the context window (memory) of even the largest models.
- State Drift: Without a robust memory architecture, the agent “forgets” why it started the task. I have seen agents enter loops where they fix a bug in File A, creating a bug in File B, then fix File B, breaking File A, endlessly burning tokens because they lost the “Global State” of the project.
The Architectural Primitives Agents Actually Need
You cannot solve these problems with prompt engineering. You solve them with Architecture. Specifically, within the AWS ecosystem (using Amazon Bedrock as the core), we are seeing a new stack emerge. This is what “Agent-Ready” infrastructure looks like:
1. Orchestration (The Nervous System)
You need a state machine, not a script. Simply looping a Python script (while task_not_complete: call_llm()) is insufficient for production. You need a durable orchestrator, such as AWS Step Functions or the native Amazon Bedrock Agents runtime.
- Why? If the Agent crashes or the API times out after 4 hours of work, you need to resume exactly where you left off.
- Human-in-the-Loop: The orchestrator allows for “Checkpoints.” Before the Agent executes a git push or a DROP TABLE, the state machine pauses, sends an SNS notification to a Senior Engineer, and waits for a manual approval token. This hybrid autonomy is critical for enterprise trust.
2. Secure Execution Boundaries (The Sandbox)
This is the single most important component for preventing hallucinations. An Agent must never execute code in the same environment that orchestrates it. If your Agent writes a Python script to analyze data, that script must run in an ephemeral, isolated sandbox—a “padded room” for code.
- The Feedback Loop: In Amazon Bedrock, this is handled via Code Interpreters. The Agent writes code -> The Sandbox executes it -> The Sandbox returns StandardOutput or StandardError.
- The “Grounding” Effect: If the Agent hallucinates a library that doesn’t exist, the Sandbox returns an ImportError. This error is the cure for hallucination. It forces the probabilistic model to confront reality and self-correct. Without a sandbox, the Agent just “guesses” that the code works.
3. Guardrails as Infrastructure
Security cannot be a polite request in the System Prompt (“Please do not leak PII”). It must be a hard infrastructure constraint. Using tools like Amazon Bedrock Guardrails, you can define “Topic Denial” and “Content Filtering” at the platform level.
- Example: If an Agent working on a frontend task tries to query the database using a tool it shouldn’t access, the Guardrail intercepts the API call and returns a “Permission Denied” signal, without the LLM even knowing it was blocked by a filter. This is “Defense in Depth” for AI.
Operationalizing Autonomy: How to Sleep at Night
Once you have the architecture, how do you monitor it? “Uptime” and “Latency” are useless metrics for an Agent. You need Semantic Observability.
The New Metrics Stack
- Pass@k (Success Rate): If the Agent runs the task 10 times, how many times does it result in passing tests?
- Tool Error Rate: A spike in this metric indicates the Agent is confused about how to use its tools (or that a tool definition is poor).
- Loop Detection: You must monitor for repetitive thought patterns. If the trace shows the Agent performing ls -la -> cat file.txt -> ls -la five times in a row, it’s stuck. Kill the process to save money.
TDD for AI: The Golden Workflow
The only way to trust an Agent is to force it to use Test-Driven Development (TDD). In your System Prompt and orchestration flow, mandate this strict sequence:
- Explore: Agent explores the codebase to understand the context.
- Reproduction: Agent must write a test script that fails (reproducing the bug).
- Verification: Agent runs the test in the Sandbox. It confirms failure.
- Implementation: Agent writes the fix.
- Validation: Agent runs the test again. It passes.
By forcing the Agent to “prove” the bug exists before fixing it, you eliminate 90% of “lazy” hallucinations where the AI claims to have fixed a problem that never existed.
The Economics of Autonomy
Finally, a note to the business leaders: Agents are expensive employees, but cheap consultants.
A single “Chain of Thought” loop for a complex software task might consume 50,000 to 100,000 tokens of input/output. On a Frontier Model, this can cost anywhere from $0.50 to $2.00 per task run.
While this is negligible compared to an engineer’s hourly rate ($100+), it is disastrous if you treat it like an API call that runs 10,000 times a minute.
Cost Control Strategy:
- Model Routing: Use a “Router” to send simple tasks (e.g., “Fix this typo”) to smaller, cheaper models (like Haiku or Llama 3 8B), and reserve the Frontier Models (Claude 3.5 Sonnet / GPT-4) only for complex reasoning tasks.
- Budgeting per Session: Implement a “Token Cap” per execution ID. If an agent hasn’t solved the problem within $5.00 of compute, it is likely lost. Cut the cord and flag for human review.
Conclusion: The “Agent-Ready” Future
We are entering a world where software builds software. The competitive advantage of the next decade won’t just be having the best developers; it will be having the best Agent Infrastructure that allows those developers to offload 40% of their drudgery to autonomous systems.
But this future is not “plug and play.” It requires a deliberate architectural shift. It requires moving away from fragile scripts and toward robust Agent Foundations: Orchestration, Sandboxing, and deep Observability.
The organizations that treat Agents with the engineering rigor of a microservice will build “Digital Factories” that run 24/7. Those that treat them like chatbots will build expensive toys.
The question is not if you will use Agents, but whether your architecture is ready to survive them.